Figure 1: LIME: Localized IMage Editing. Our method edits an image based
on a single text prompt without needing customized datasets
or fine-tuning. The four examples are taken from established papers [25, 46, 47] and compare our edits with the respective state-of-the-art
models. The addition of LIME improves all models and allows localized edits that preserve the rest of the image untouched.
Abstract
Diffusion models (DMs) have gained prominence due to their ability to generate high-quality, varied images, with recent advancements in text-to-image generation. The research focus is now shifting towards the controllability of DMs. A significant challenge within this domain is localized editing, where specific areas of an image are modified without affecting the rest of the content. This paper introduces LIME for localized image editing in diffusion models that do not require user-specified regions of interest (RoI) or additional text input. Our method employs features from pre-trained methods and a simple clustering technique to obtain precise semantic segmentation maps. Then, by leveraging cross-attention maps, it refines these segments for localized edits. Finally, we propose a novel cross-attention regularization technique that penalizes unrelated cross-attention probabilities in the RoI during the denoising steps, ensuring localized edits. Our approach, without re-training and fine-tuning, consistently improves the performance of existing methods in various editing benchmarks.
Method
Edit Localization
Segmentation
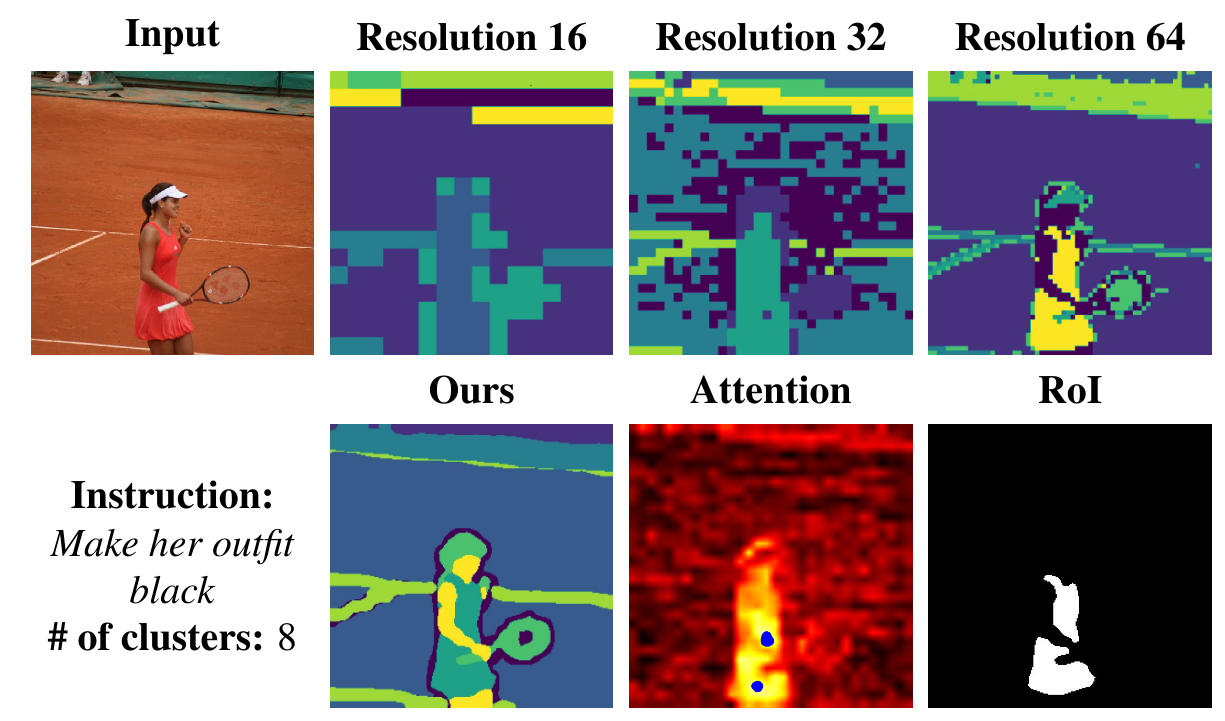
The segmentation approach differs from previous methods by utilizing InstructPix2Pix (IP2P) and targeting features conditioned on the original image. It leverages multiple layers of the U-Net architecture to extract features, favoring intermediate features over attention maps due to their superior semantic encoding capabilities. This process involves a multi-resolution fusion strategy, combining feature maps of different resolutions to improve segmentation accuracy. Different resolutions capture varying semantic components, as seen Fig. 2, and their fusion results in more robust feature representations.
Localization
For localization, our method identifies the Region of Interest (RoI) using cross-attention maps that are conditioned on both the input image and the edit instructions. These maps undergo resizing, combining, and normalization processes to focus on relevant text tokens, thereby identifying areas related to the editing instructions. A final cross-attention map is created to pinpoint the most significant pixels, and segments overlapping these pixels are combined to determine the RoI. This approach ensures precise and relevant localization for image edits.
Figure 2: Segmentation and RoI finding.Resolution Xs
demonstrates segmentation maps from different resolutions, while Ours
shows the segmentation map from our method. For the cross-attention map, the color yellow indicates high probability, and blue
dots mark the 100 pixels with the highest probability. The last image shows the extracted RoI using blue dots and Ours.
Edit Application
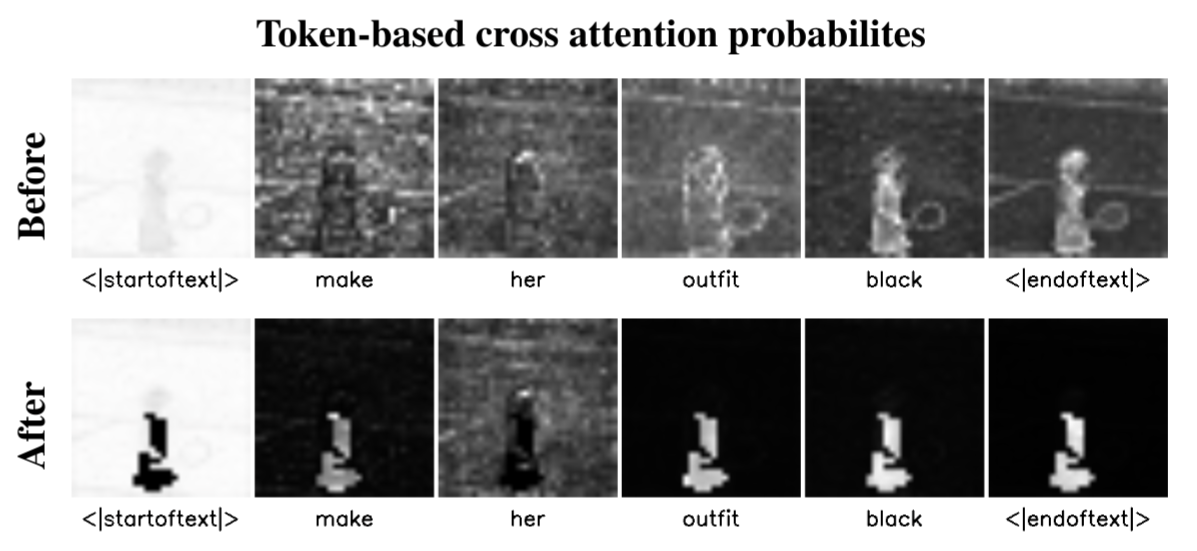
This section describes a localized editing technique within the IP2P framework, designed to manipulate attention scores in the RoI while maintaining the integrity of the rest of the image. This technique diverges from previous methods by focusing on attention scores rather than noise space. It involves a targeted attention regularization process that selectively reduces the influence of unrelated tokens (e.g., < start of text >, padding, and stop words) within the RoI. The process adjusts the attention scores within the RoI to minimize the impact of these unrelated tokens during the softmax normalization, ensuring that higher attention scores are assigned to tokens relevant to the editing instructions.
Attention Regularization
The attention regularization approach enhances the precision and effectiveness of edits by ensuring they are focused on the intended areas without affecting the surrounding context. The method employs a sophisticated regularization technique that modifies the dot product of cross-attention layers for unwanted tokens, essentially reducing their influence in the RoI. By doing so, it achieves an optimal balance between targeted editing and preserving the original image context. This technique improves the localization of edits in the IP2P model without requiring additional training or fine-tuning, thus conserving computational resources and time.
Figure 3: Attention Regularization. Our method selectively regularizes unrelated tokens within the RoI, ensuring precise, context-aware edits without the need for additional model training. After attention regularization, the probabilities for the related tokens are
attending the RoI, as illustrated in the second row.
Experiments
Qualitative Results
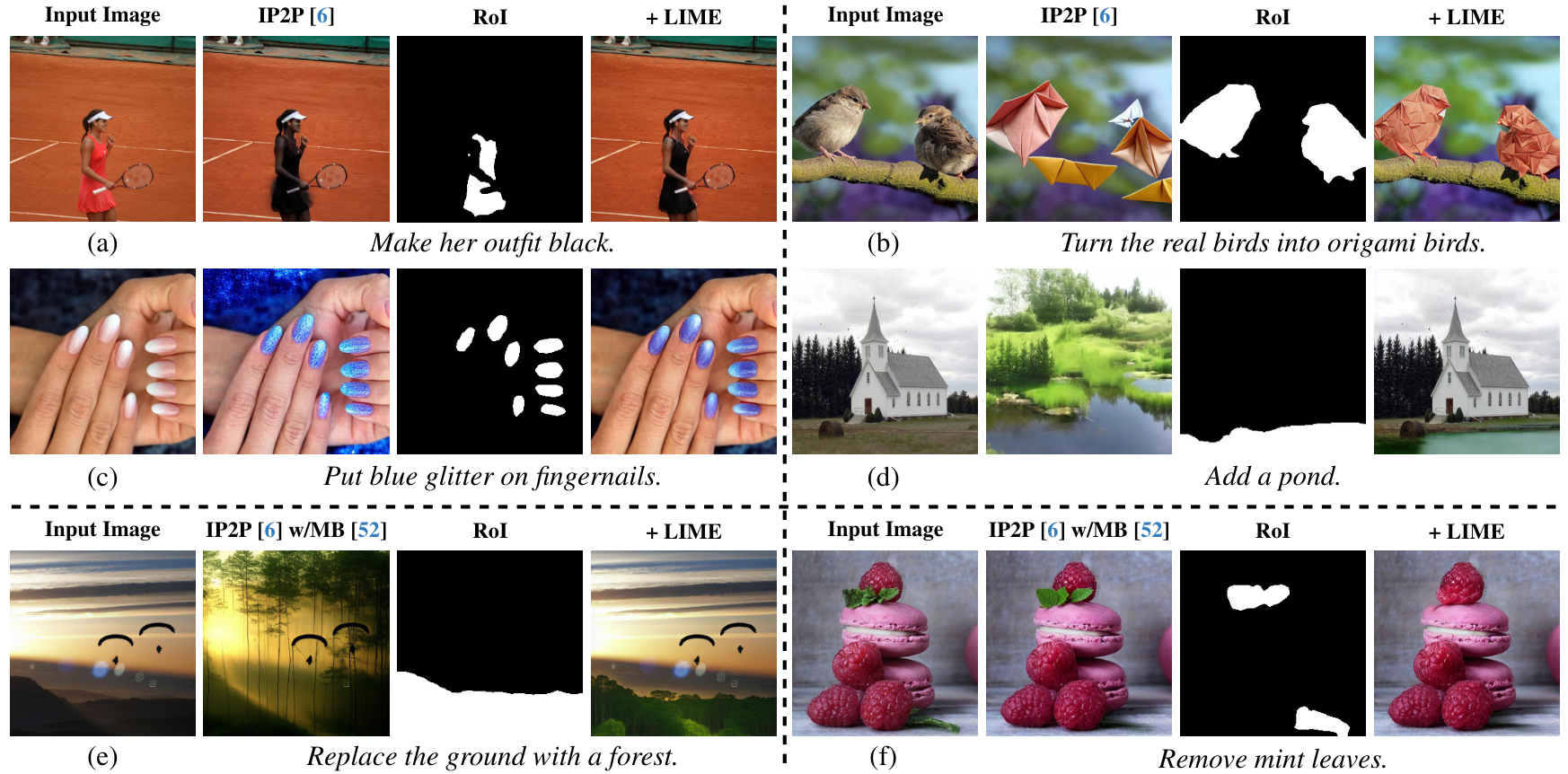
Figure 4 presents qualitative examples for various editing tasks. These tasks include editing large segments, altering textures, editing multiple segments simultaneously, and adding, replacing, or removing objects. The first column displays the input images, with the corresponding edit instructions below each image. The second column illustrates the results generated by the base models without our proposed method. The third and fourth columns report the RoI identified by our method and the edited output produced by the base models when our regularization method is applied to these RoIs. As shown in Fig. 4, our method effectively implements the edit instructions while preserving the overall scene context.
In all presented results, our method surpasses current state-of-the-art models, including their fine-tuned versions on manually annotated datasets, e.g., MagicBrush. Furthermore, without additional training, IP2P cannot perform a successful edit for (d) in Fig. 4 as also reported in HIVE. However, our proposed method achieves the desired edit without any additional training on the base model as shown Fig. 4 - (d).
Figure 4: Qualitative Examples. We test our method on different tasks: (a) editing a large segment, (b) altering texture, (c) editing multiple
segments, (d) adding, (e) replacing, and (f) removing objects. Examples are taken from established papers [20, 52, 53]. The integration of
LIME enhances the performance of all models, enabling localized edits while maintaining the integrity of the remaining image areas.
Quantitative Results
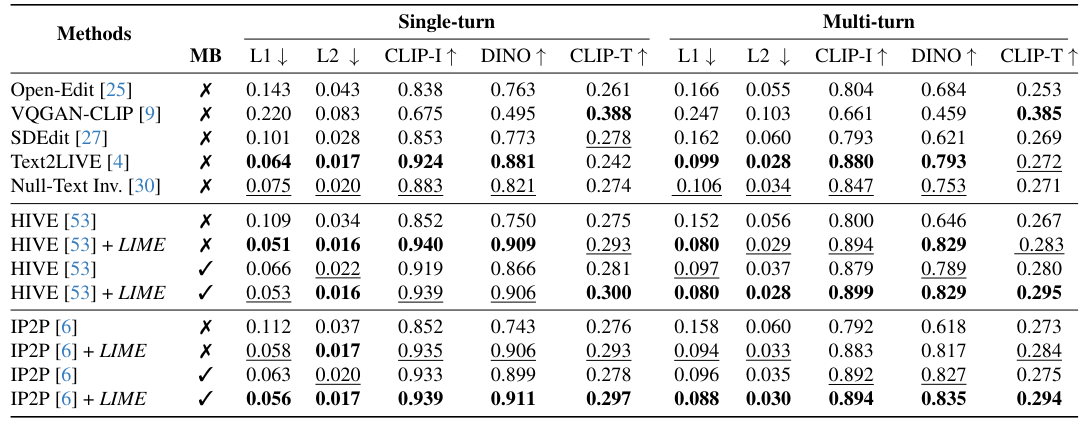
Our method outperforms all other methods on both the single- and multi-turn editing tasks on MagicBrush~(MB) benchmark, as seen in Tab. 1. Compared to the base models, our approach provides significant improvements and best results in terms of L1, L2, CLIP-I, and DINO. For the CLIP-T metric, which compares the edited image and caption to the ground truth, our method comes very close to the oracle scores of 0.309 for multi-turn and 0.307 for single-turn. This indicates that our edits accurately reflect the ground truth modifications. VQGAN-CLIP achieves the highest in CLIP-T by directly using CLIP for fine-tuning during inference. However, this can excessively alter images, leading to poorer performance in other metrics. Overall, the performance across metrics shows that our approach generates high-quality and localized image edits based on instructions, outperforming prior state-of-the-art methods.
Table 1: Evaluation on MagicBrush Datase. Results for single-turn and multi-turn settings are presented for each method and MB
stands for models fine-tuned on MagicBrush. The benchmark values for other approaches are sourced from MagicBrush, while values for our
proposed method are computed following the same protocol. Across both settings, our method surpasses the base models performance of
the compared models. The top-performing is highlighted in bold, while the second-best is denoted with underline for each block.
Discussion
Use-case
Figure 5 illustrates the application of our method in localized image editing tasks. Specifically, it demonstrates our method's proficiency in altering the color of specific objects: (a) ottoman, (b) lamp, (c) carpet, and (d) curtain. Unlike the baseline methods, which tend to entangle the object of interest with surrounding elements, our approach achieves precise, disentangled edits. This is not achieved by the baseline that tends to alter multiple objects simultaneously rather than isolating changes to the targeted region. The disentangled and localized edits showcased in Fig. 5 highlight the potential of LIME in end-user applications where object-specific edits are crucial.
In this paper, we introduce, LIME a novel localized image editing technique using IP2P modified with explicit segmentation of the edit area and attention regularization. This approach effectively addresses the challenges of precision and context preservation in localized editing, eliminating the need for user input or model fine-tuning/retraining. The attention regularization step of our method can also be utilized with a user-specified mask, offering additional flexibility. Our method's robustness and effectiveness are validated through empirical evaluations, outperforming existing state-of-the-art methods. This advancement contributes to the continuous evolution of LDMs in image editing, pointing toward exciting possibilities for future research.
Limitations
Figure 6 shows limitations of our method: (i) shows the limitation due to the pre-trained base model's capabilities. Our method can focus on the RoI and successfully apply edits but may alter the scene's style, particularly in color, due to the base model entanglement. However, our proposal significantly improves the edit compared to IP2P. (ii) illustrates how prompt content impacts edit quality. During editing, all tokens except <start of text>, stop words, and padding, affect the RoI, leading to feature mixing.
Figure 6: Failure Cases & Limitations. Left: Base model entan-
glement. Right: Feature mixing issue.
BibTeX
@InProceedings{Simsar_2025_WACV,
author = {Simsar, Enis and Tonioni, Alessio and Xian, Yongqin and Hofmann, Thomas and Tombari, Federico},
title = {LIME: Localized Image Editing via Attention Regularization in Diffusion Models},
booktitle = {Proceedings of the Winter Conference on Applications of Computer Vision (WACV)},
month = {February},
year = {2025},
pages = {222-231}
}