



3D GANs have the ability to generate latent codes for entire 3D volumes rather than only 2D images. These models offer desirable features like high-quality geometry and multi-view consistency, but, unlike their 2D counterparts, complex semantic image editing tasks for 3D GANs have only been partially explored. To address this problem, we propose LatentSwap3D, a semantic edit approach based on latent space discovery that can be used with any off-the-shelf 3D or 2D GAN model and on any dataset. LatentSwap3D relies on identifying the latent code dimensions corresponding to specific attributes by feature ranking using a random forest classifier. It then performs the edit by swapping the selected dimensions of the image being edited with the ones from an automatically selected reference image. Compared to other latent space control-based edit methods, which were mainly designed for 2D GANs, our method on 3D GANs provides remarkably consistent semantic edits in a disentangled manner and outperforms others both qualitatively and quantitatively. We show results on seven 3D GANs (pi-GAN, GIRAFFE, StyleSDF, MVCGAN, EG3D, StyleNeRF, and VolumeGAN) and on five datasets (FFHQ, AFHQ, Cats, MetFaces, and CompCars).
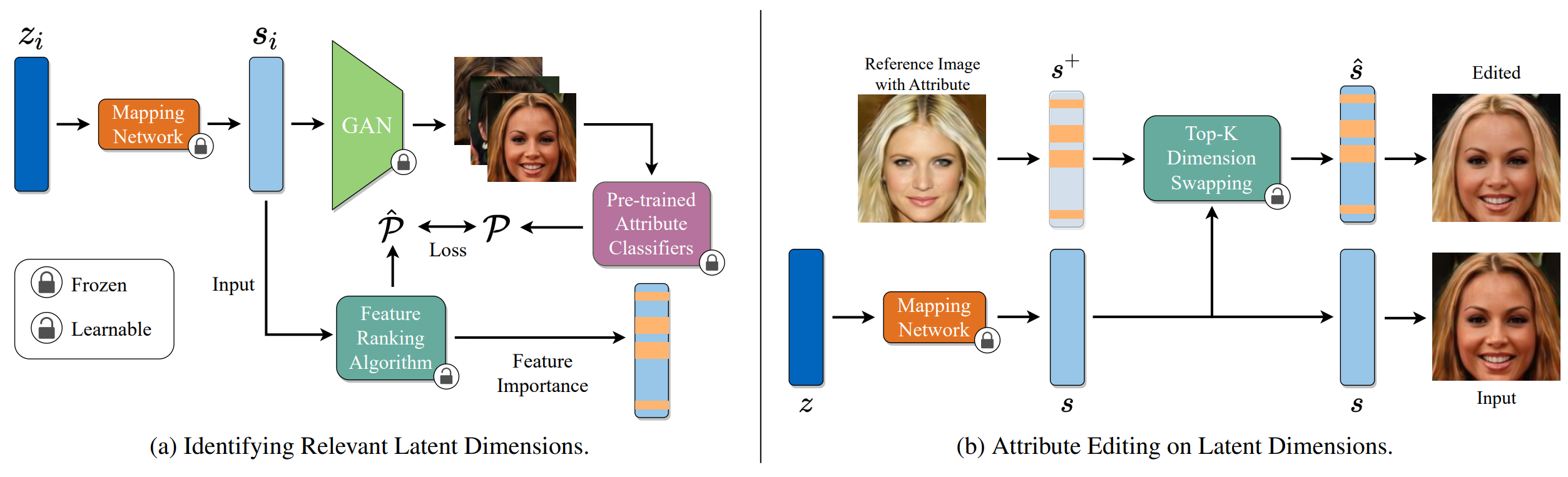
We aim to build a model agnostic method that can work on any 3D-aware image generator. Our method, LatentSwap3D, consists of two main components. The first one identifies important features in the latent space of a 3D GAN that controls the desired attribute through a random forest algorithm. Then, the target attribute is manipulated in an identity-preserving manner through a feature-swapping approach.
GIRAFFE consists of NeRF and 2D GANs. The NeRF part outputs the features of the 3D shape and texture, while the 2D GAN part outputs the final image. Figure 3 shows smiling and wearing eyeglasses edits from LatentSwap3D on the GIRAFFE - FFHQ model following the same protocol detailed for the other FFHQ trained generators.

To test how well LatentSwap3D generalizes to different datasets we extended the experiment to include CompCars using the pre-trained GIRAFFE generator. Due to the lack of classifiers for car attributes, as a proof of concept, we trained a ResNet-50 to classify the color of a car from scratch on Myauto.ge Cars Dataset. As seen from Fig. 4, using these classifiers our approach can edit the color of the cars successfully.

StyleNeRF is another high-resolution 3D-aware generative model that integrates a NeRF into a 2D style-based generator. StyleNeRF is able to generate high-resolution and 3D consistent images/shapes from unstructured 2D images. Figure 5 shows our attribute editing, e.g., smiling, removing bangs, and changing the hair color to blond, on StyleNeRF - FFHQ.

VolumeGAN is a high-quality 3D-aware generative model explicitly trained to learn a structural and a textural representation and it is based on NeRF. The results of our approach on VolumeGAN - FFHQ are provided in Fig. 6. Our approach applies the desired attributes, e.g., removing eyeglasses, changing the hair color, and reducing the facial hair, to the latent space of VolumeGAN, without changing the identity of the input face.

LatentSwap3D is not limited to 3D-aware GANs but also works on image-based GANs like StyleGAN2, see Fig. 7. First, by applying the same procedure in Fig. 2(a), we identify the latent codes from the style space of StyleGAN2 that are most important for the desired attribute. Then, we swap these latent codes to generate the desired edits, as explained in Fig. 2(b).

@InProceedings{Simsar_2023_ICCV,
author = {Simsar, Enis and Tonioni, Alessio and Ornek, Evin Pinar and Tombari, Federico},
title = {LatentSwap3D: Semantic Edits on 3D Image GANs},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2023},
pages = {2899-2909}
}We are grateful to Google University Relationship GCP Credit Program for the support of this work by providing computational resources.